Configuring a Sunlight Cluster for High Availability
For production settings it is often important to configure the system for the absolute best uptime and availability of the services that are running on the cluster. Failures can happen at various levels of the system, and in this section we describe the types of failures to consider and the ways in which Sunlight can be configured to stay resilient against each.
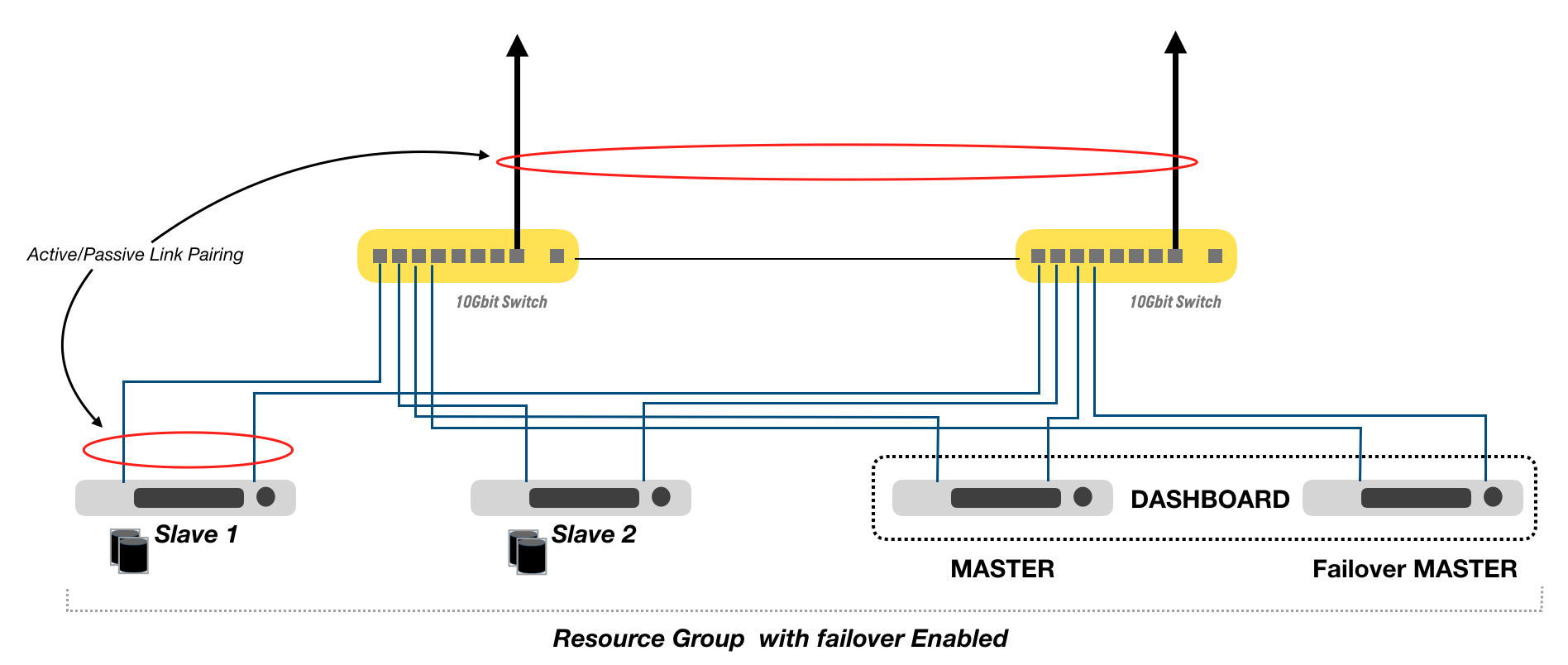
Network path failure
Network path failures can occur because a direct connected switch fails, is powercycled or a link is physically removed. Furthermore a physical NIC interface on the host may itself experience failure e.g. due to electrical interference or a power surge. The Sunlight cluster can be configured to be resilient to all of these failure scenarios by following these guidelines:
- Every NexVisor (Hypervisor) host in the cluster must have more than one Network Interface port. All these interfaces must be operating at the same link speed and with the same MTU of 9K or above configured on the switch ports. The switch must enable both ports in exactly the same direct connected subnet or with the same VLAN access if VLAN tagging is enabled.
- Add more than one physical PCIe attached NIC card (i.e. not with the ports on the same PCIe card). It is common to have multiport on-board NICs on a motherboard. Adding one or more independent NIC cards can help to provide hardware NIC redundancy. Ensure that port failover policies are paired across the independent PCIe NICs
- Use redundant switch infrastructure and ensure that every NexVisor host is attached to more than one physical switch to provide tolerance against whole switch failure.
- Configure VM attached networks with a physical NIC failover policy and select the correct NICs to pair together in an Active/Passive mode
Storage drive failure
The storage access path between physical sunlight nodes will use all available network paths, always guaranteeing network path redundancy in the event of any of the failures outlined above. It is critical however to ensure that the datastore for every Highly available VM has been initialised with a redundant mirroring policy. When mirroring is enabled the Sunlight cluster will always ensure that VM data volumes are spread across distributed nodes to tolerate against both drive and system failure. Note that you can configure the resource group to be tolerant across blades, chassis and even across racks, so the datastore drive members must reflect the same policy.
Server failure
A complete server may fail, e.g. due to PSU failure (quite rare in the case of redundant power supplies in a server) or due to some other internal failure such as an electrical fault of the motherboard. To protect against this it is necessary to create a resource group failover policy that ensures that all VMs required to be highly available belong to a failover policy. The resource group will define the failover policy as being either across blade, across chassis or across rack level. The administrator must ensure that the correct resources are selected in order to honour the failover policy.
Configuring the VM failover policy
The Resource Group must be configured with an appropriate VM failover policy in order to ensure that the system is resilient to node failure. Follow the instructions under Resource Group confgiuration and select the High Availabilty setting required. Sufficient resources must be allocated to support failover.
Configuring the Sunlight dashboard service to be highly available
In the current release you must designate separate nodes to handle the dashboard failover in an active/passive mode as illustrated above. Note also that you must create one or more Datastores that are enabled to store metadata. Two nodes should be pre-installed as a master with one powered off in preparation for failover. In the event of failure of the master node, remove power to the first master and power on the passive node. The database should be restored from one of the redundant datastores in order to bring the controller back to the latest state.
Note
Automated controller failover will be enabled in an upcoming release. At this time it will not be necessary to install separate infrastructure to host the Sunlight controller, the failover policy will be fully hyperconverged.
High Availability Checklist
Once your cluster is fully configured to be highly available following all the guidelines above we strongly recommend that you follow the following checklist to ensure that you are ready in the event of failure:
-
Deploy some test VMs in a Resource Group that is configured with High availability and ensure they have access to both internal virtual network resources and external network resources.
-
Remove one cable from a node and validate VM liveness. Replace the cable once complete.
-
Remove another cable from a node and validate VM liveness. Replace the cable once complete.
-
Power off a switch and validate VM liveness for all VMs and for the Sunlight dashboard controller. Power the switch back on once complete.
-
Power off a node and wait for failover maximum time + VM boot up time. Validate VM liveness for all VMs and for the SUnlight dashboard controller. Power the node back on once complete.
-
Physically remove a storage drive from one of the nodes. Validate VM liveness ensuring in particular that the VM can Read and Write from it's root storage device. Validate also that the virtual disks of any VMs using that storage device become degraded. Rebooting the node with the drive inserted again will bring the disk back online again and the vDisks will all become repairable.