Automatic Master Failover
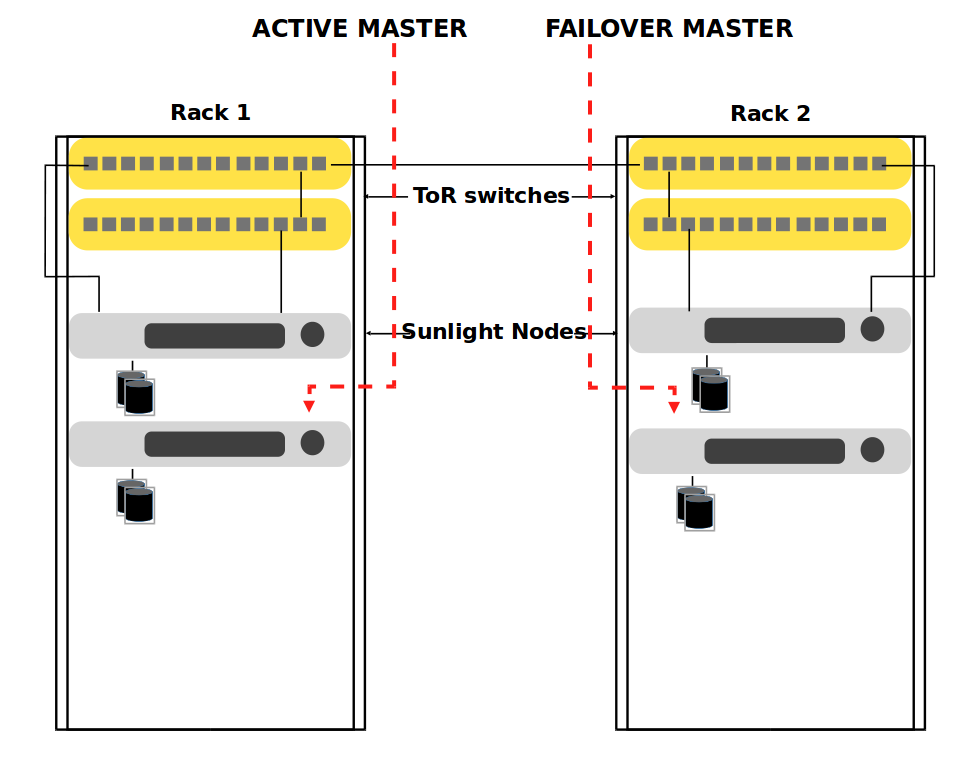
Failover is the process through which, following a node failure, resources in a cluster switch node ownership, starting on a different node in the server cluster. Specifically, a failover cluster is a couple of independent nodes that cooperate, in order to increase the availability and scalability of clustered cloud applications and services. In case one of the active master nodes fails, one candidate passive node starts to provide services by recovering the failed node. In addition, the clustered roles are proactively monitored by Sunlight scheduler to verify that active master node is working properly. If, for any reason, the master node suddenly fails/crushes or does not respond, its applications and services are transferred and booted up at another slave node which is redefined as the failover master node.
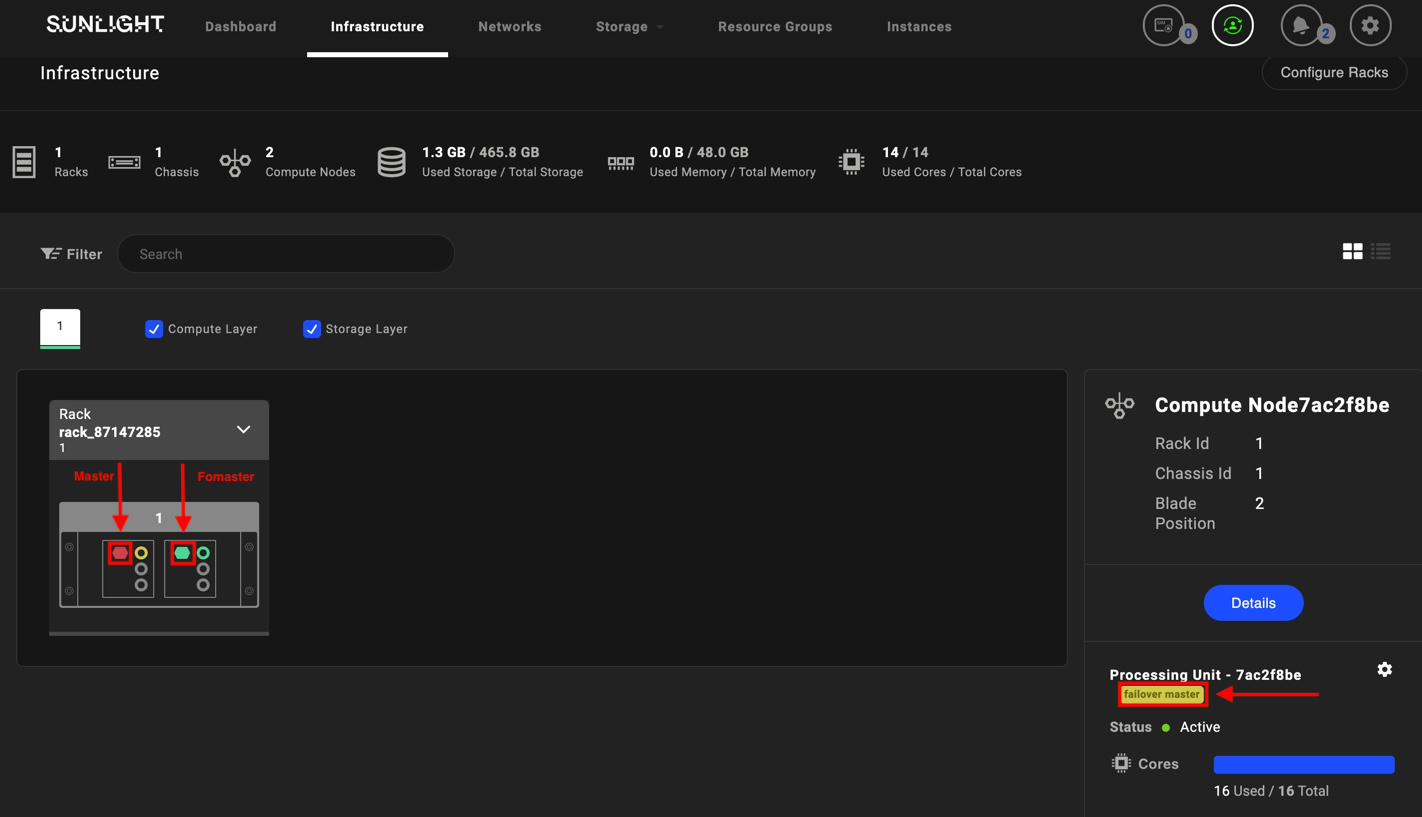
Sunlight.io provides automatic master node failover. This is a built-in mechanism which detects and determines when a master node is unavailable, initiating one of the existing passive nodes to takeover the master role. The following diagram illustrates the Sunlight high availability infrastructure in a top rack level. Rack 1 consists of active master nodes that are tightly connected through a ToR switch to the Rack 2 which is composed of their corresponding failover master nodes (passive masters).Each active master corresponds to one passive failover master. Once an active master fails or is not responsive, its corresponding failover node becomes the master of the cluster.
Warning
In case the failed master node becomes active again, the current active master node is demoted to its previous state, a failover master.
Enable Master Fault Tolerance
In order to enable master fault tolerance, visit the 'Infrastructure' tab and follow the next steps:
-
Specifying one slave node as failover master : Hover over the desired slave node (candidate failover), click on the configuration option and select 'Enable FT'
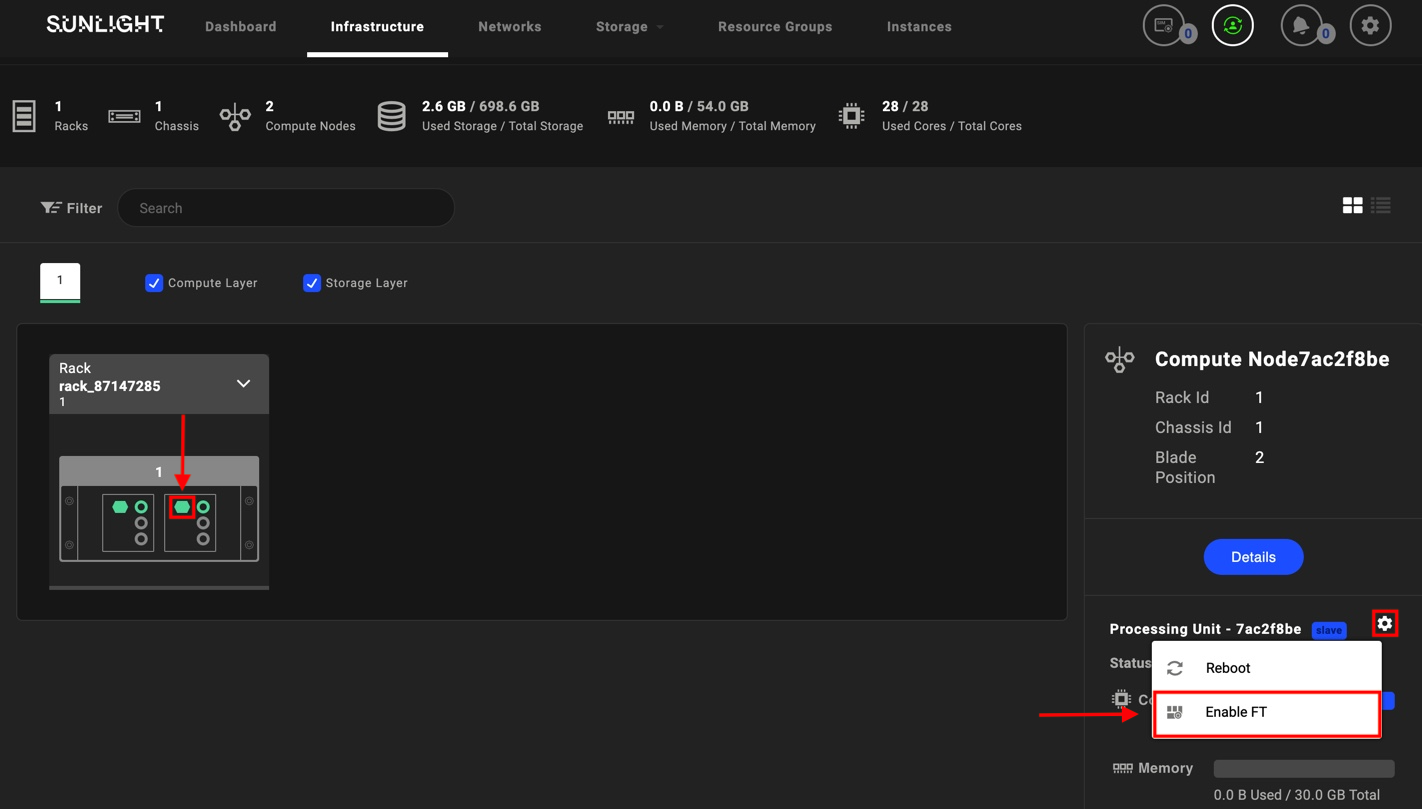
-
The user is then requested to confirm the FT enable action. Press OK to proceed.
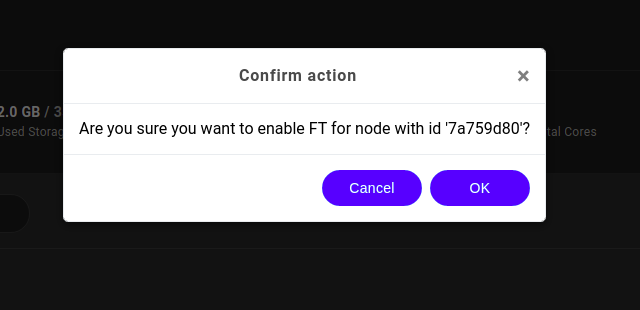
The automatic failover feature for master node has now been activated.
Warning
In order for the master fault tolerance to be supported, a datastore with the following specifications should be created.
a. 2 Replica Selected
AND
b. DB metadata Enabled
Disable Master Fault Tolerance
In order to disable master fault tolerance, visit the 'Infrastructure' tab and follow the next steps:
-
Hover over the failover node (highlighted in a bright yellow color), click on the configuration option and select 'Disable FT'
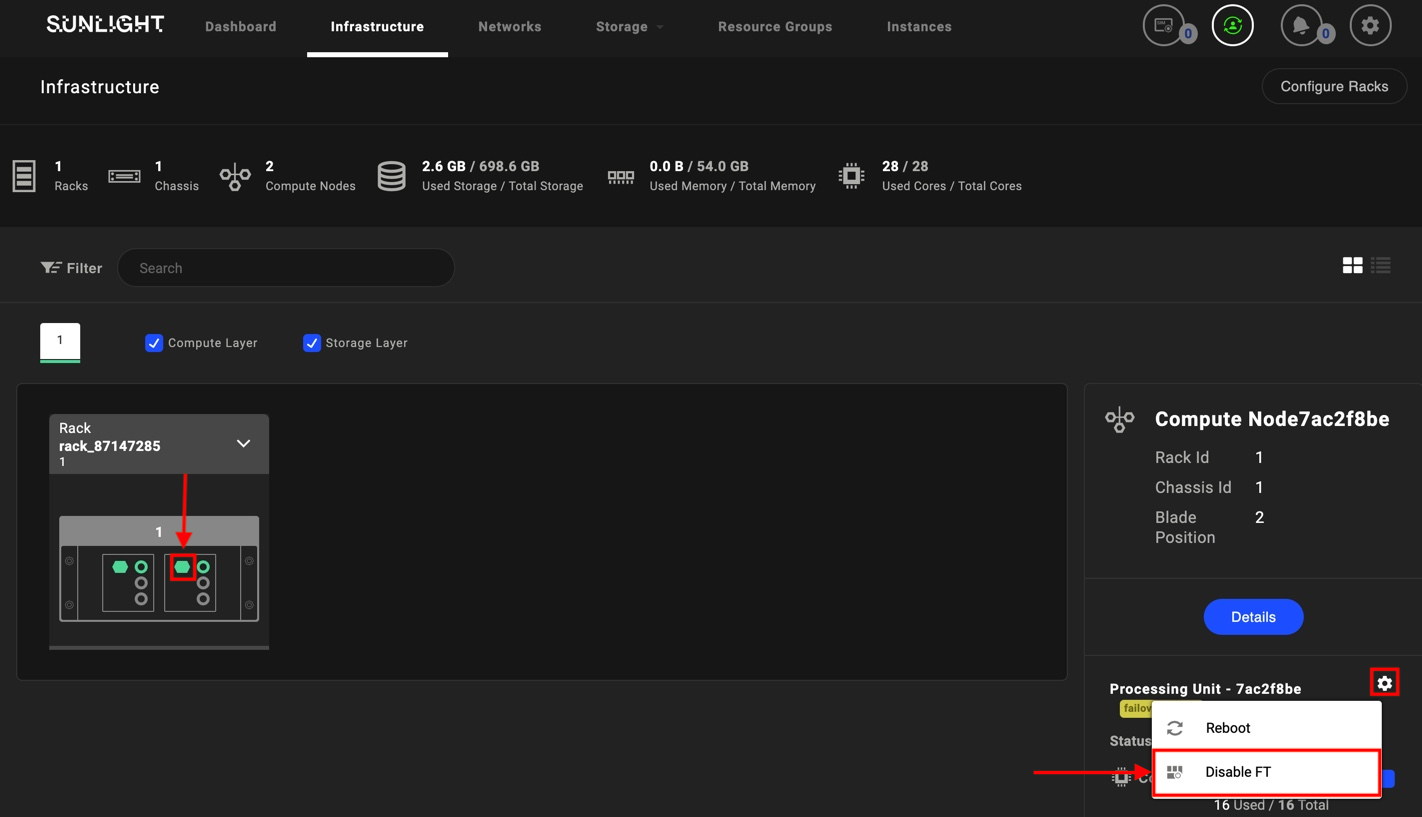
-
The user is then requested to confirm the FT disable action. Press OK to proceed.
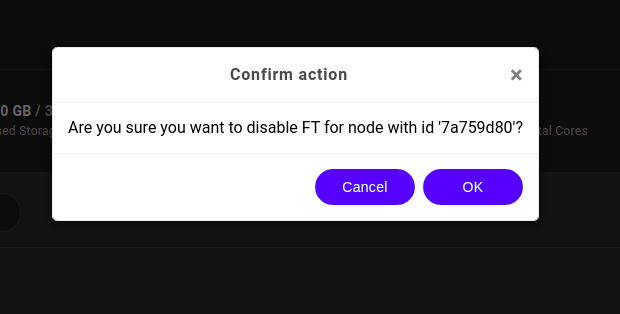
Upon FT disable action confirmation, master node failover is not any longer supported by the system.
Failover Master Use Case
In this use case we examine the possibility where the master node has crashed or has completely lost its network connectivity , while the master failover functionality has been properly configured.
The UI dashboard will not be reachable for a while, following the crash of the master node. This may last for a few minutes, until the synchronization of the database between the nodes is completed. While the user attempts to login to the UI dashboard, a splash page is displayed, informing that fault tolerance has been activated and the UI dashboard will be available soon. In case the splash page is not displayed, a re-login attempt after a few minutes is required.

Following the successful completion of the database synchronization, the UI dashboard is displayed again.
The image below depicts the successful recovery of the master node on the failover master:
In case the crashed node is back in a healthy status and is re-activated, it can be booted and promoted as master node again. While the user attempts to login to the UI dashboard, the splash page will be displayed again, until the initialization of the database has been completed on the master node.
In case a fault occurs during the master failover process, a page containing information of the appropriate recovery actions will be displayed.
The following image displays a case where the database recovery has failed and the system recommends the user to enable the support session, in order to contact the technical staff.
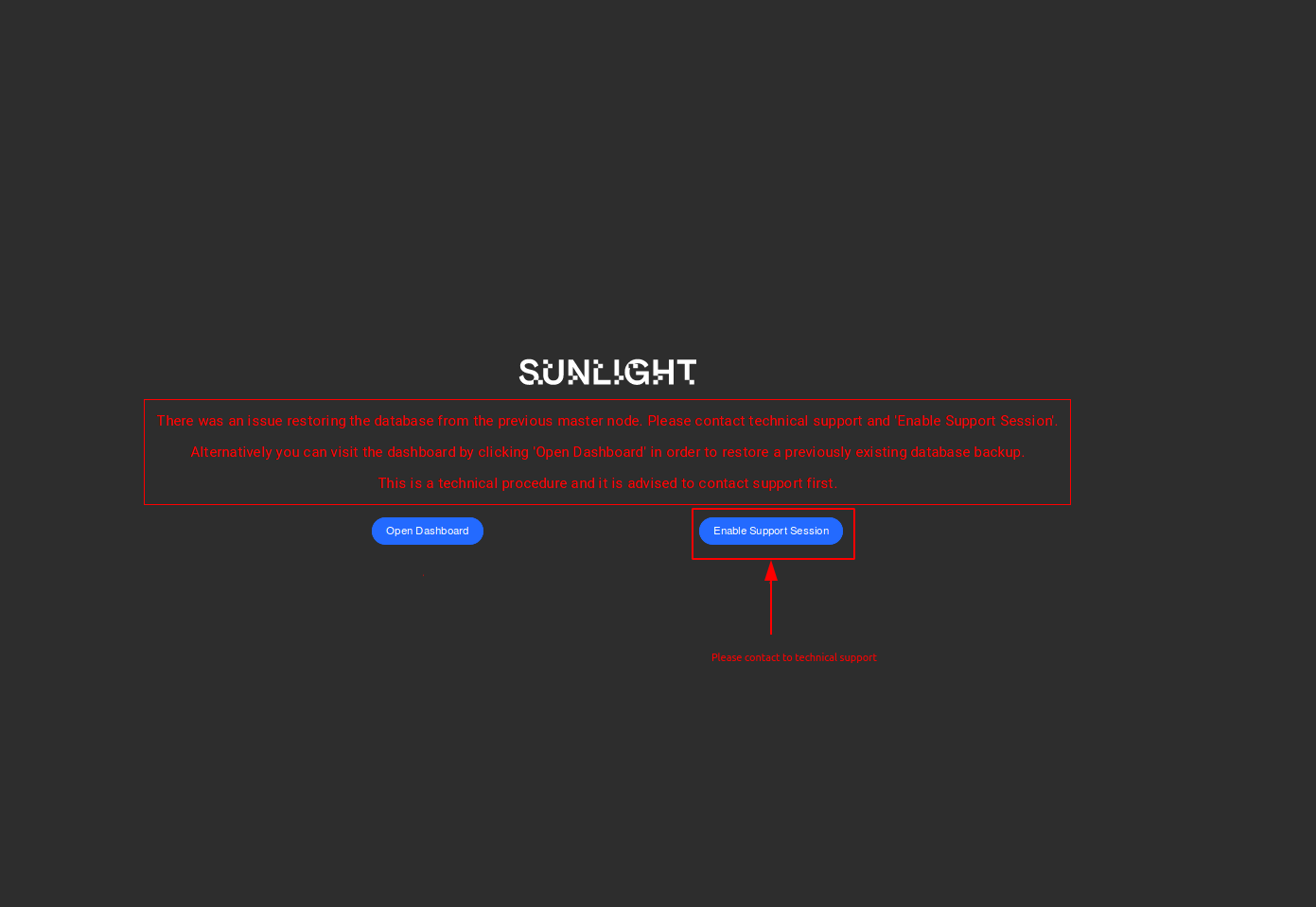
An alternative available option for accessing the dashboard is to restore the system from a previous database backup.
